LLMs Decoded: Architecture, Training, and How Large Language Models Really Work
Learn how GPT, Claude, and Mistral actually work. This visual guide decodes LLM architecture, training, tokenization, and generation—perfect for developers, students, and AI enthusiasts.
Large Language Models (LLMs) like GPT-4o, Mistral, Claude, and Gemini have transformed how we interact with AI. But what’s really happening inside these models? How do they generate coherent text, code, and even images?
This deep-dive article breaks down how LLMs are designed, trained, and how they actually work — without overwhelming you with jargon.
🧠 What is an LLM?
A Large Language Model is an AI system trained on massive text datasets to understand and generate human-like language. It can answer questions, write essays, summarize documents, translate languages, write code, and more.
Popular LLMs in 2025 include:
- GPT-4o (OpenAI)
- Claude 3 (Anthropic)
- Gemini 1.5 (Google DeepMind)
- Mistral / Mixtral (Open-source)
- LLaMA 3 (Meta)
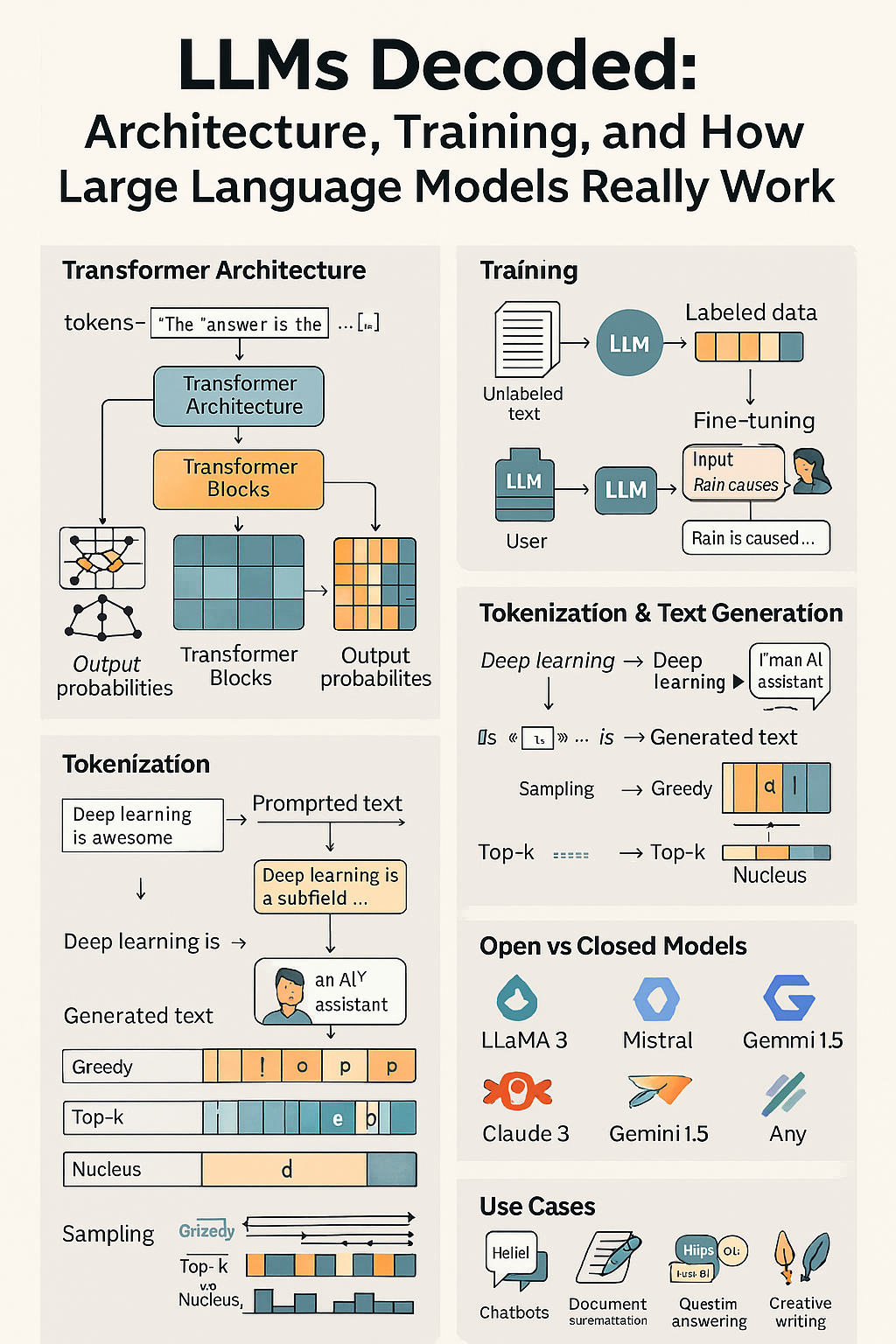
⚙️ The Core Architecture: Transformers
LLMs are built on a neural network architecture called the Transformer, introduced in the 2017 paper "Attention is All You Need".
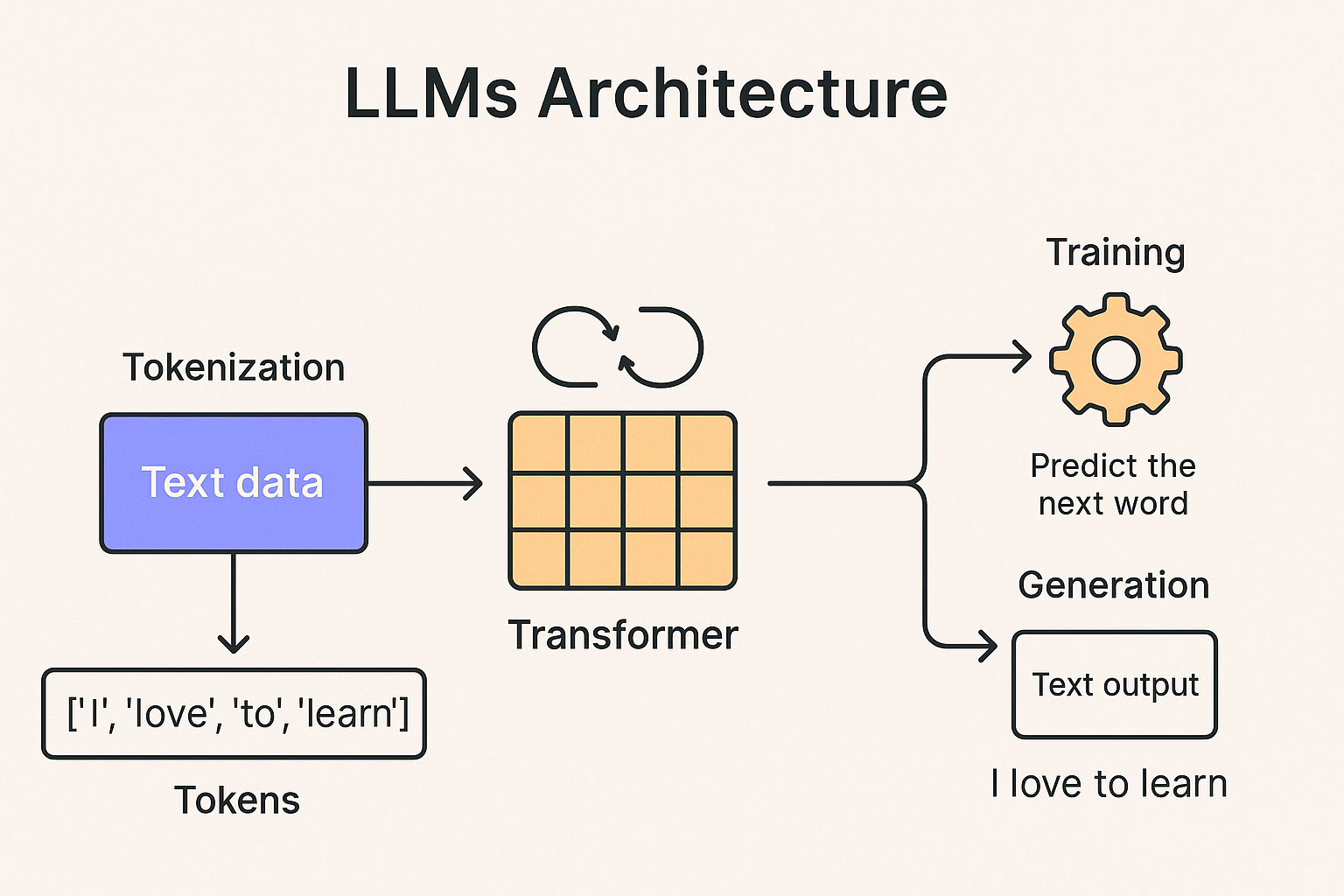
🔄 Transformer Flow:
- Input Text → Tokens: The input is split into tokens (usually subwords).
- Embedding Layer: Each token is converted into a dense vector.
- Positional Encoding: Since Transformers don’t process text sequentially, positional encodings give tokens a sense of order.
- Self-Attention Layers: Each token can "attend to" every other token in the input to gather context.
- Feedforward Layers: Add non-linearity and abstraction.
- Stacked Layers: Deep LLMs use dozens or hundreds of such layers.
- Output Prediction: The model predicts the next token (auto-regressively) based on all previous ones.
Self-Attention = Context Awareness The self-attention mechanism helps the model weigh which parts of the input are most relevant when generating a new token.
🏋️♂️ How Are LLMs Trained?
LLMs learn by predicting the next word in a sentence. They are trained on trillions of tokens from books, websites, code, conversations, and more.
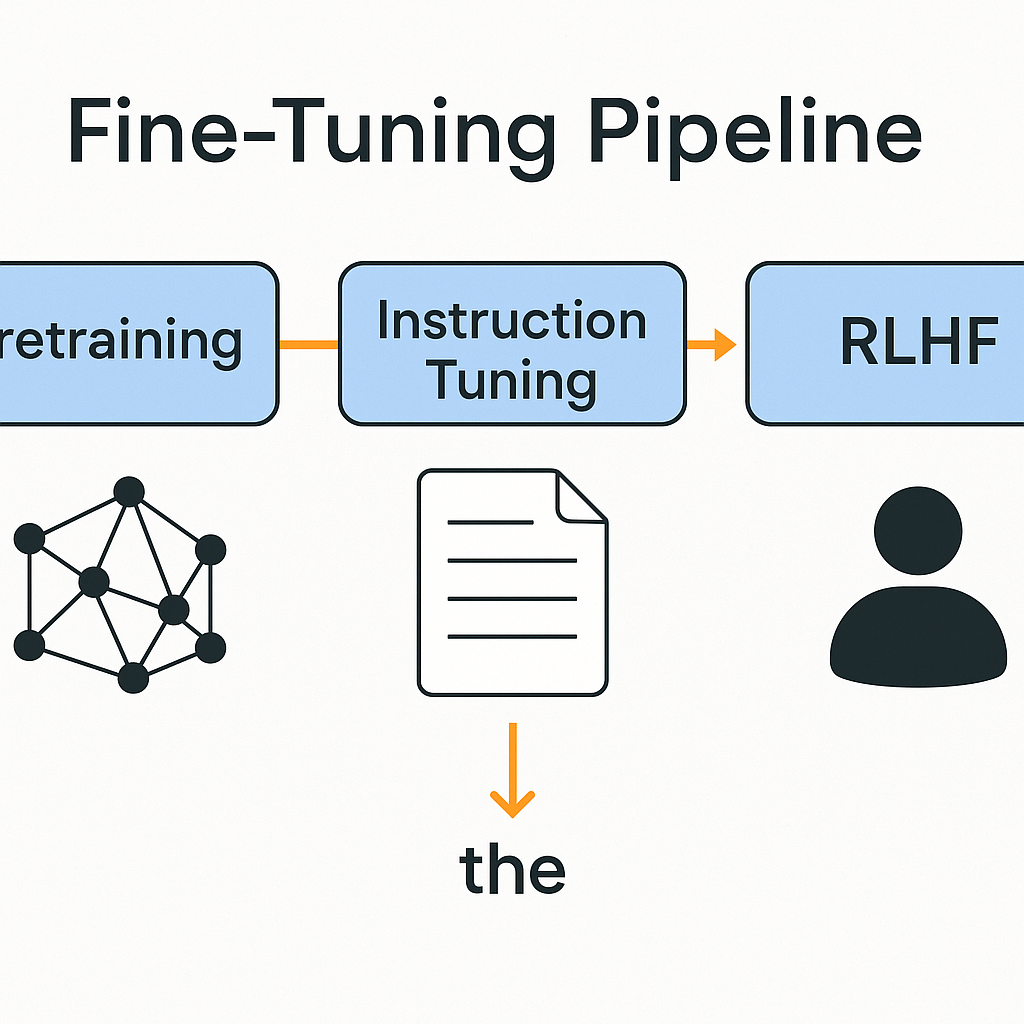
🧩 Phases of Training:
- Pretraining: Trained on general text using objectives like next-token prediction or masked language modeling.
- Fine-tuning: Refined on specific tasks or domains (e.g., medical, legal).
- Instruction-Tuning: Trained to follow instructions like "summarize this" or "write code."
- RLHF (Reinforcement Learning with Human Feedback): Aligns responses with human preferences by ranking outputs.
💻 Requirements:
- Massive datasets (Common Crawl, Wikipedia, books)
- GPUs/TPUs with high memory (A100, H100, L40)
- Weeks or months of training time
🔣 Tokenization: The Input Language of LLMs
LLMs don’t read text like we do. Instead, they process input as tokens — chunks of words or characters.
Example:
"Understanding transformers" → ['Understanding', 'transform', 'ers']Tokenizers (like SentencePiece, BPE) split input into a consistent format for embedding.
🧮 Sampling and Generation Techniques
When an LLM generates text, it predicts one token at a time. But it doesn’t just pick the highest probability every time.
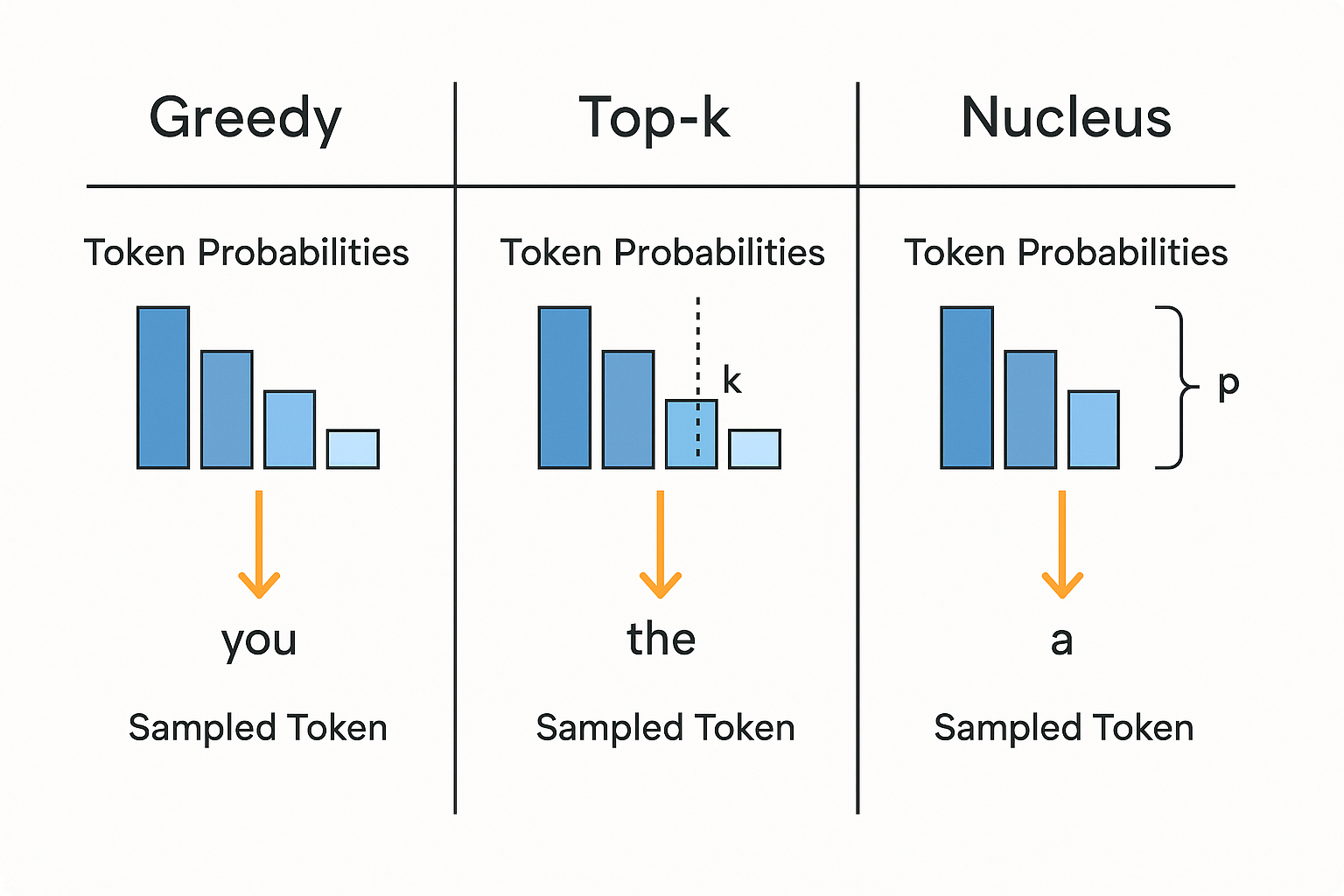
🔄 Common Sampling Strategies:
- Greedy Search: Always picks the highest probability token
- Top-k Sampling: Considers the top k likely tokens
- Top-p (Nucleus) Sampling: Chooses from tokens whose combined probability mass is > p
- Temperature: Controls randomness (higher = more diverse output)
🤯 Why Do LLMs Hallucinate?
- LLMs don’t “know” facts — they generate based on patterns in training data
- If context is unclear or missing, they confidently generate plausible but incorrect answers
- That’s why grounding with RAG or external tools is important
⚖️ Open-Source vs Closed-Source LLMs
| Feature | Open Source (e.g., Mistral, LLaMA) | Closed (e.g., GPT, Claude) |
|---|---|---|
| Cost | Free / Self-hosted | Paid API |
| Customization | High (fine-tune, modify) | Limited |
| Performance | Competitive with closed models | Best-in-class (GPT-4o) |
| Privacy | Full control | Depends on provider |
💡 Real-World Applications
- Chatbots (customer support, education, HR)
- Code Generation (Copilot, Cody, GPT Engineer)
- Data Analysis (text-to-SQL, pandas assistants)
- Search & Summarization (search engines, legal docs)
- Creative Work (music, lyrics, novels, design prompts)
🔮 The Future of LLMs
- Multimodal Models: LLMs like GPT-4o and Gemini handle text, image, audio, and video
- Smaller Efficient Models: Distilled, quantized models for on-device usage
- Personal AI Agents: Trained on your own documents, behavior, and preferences
- Better Alignment: Reducing bias, hallucinations, and ethical concerns
✅ Conclusion
Large Language Models are the foundation of modern AI — from chatbots to copilots to research tools. By understanding how they work, you’re better prepared to use, build, and even train your own models.
Stay tuned for follow-up articles on:
- Fine-tuning vs Prompt Engineering
- Comparing LLaMA 3, GPT-4o, and Claude 3
- Building your own mini-LLM with 1B parameters
AK Newsletter
Join the newsletter to receive the latest updates in your inbox.